
- Scientists have shown that a cutting-edge type of artificial intelligence can automatically count, identify, and describe the behaviors of 48 animal species in camera trap images taken in the Serengeti ecosystem.
- The team used a dataset of 3.2 million wildlife images to train and test deep convolutional neural networks to recognize not only individual animals but also what the animals are doing in each image.
- The models performed as well as human volunteers in identifying, counting, and describing the behavior of animals in nearly all the Serengeti camera trap images and also identified those images that required human review.
- The widespread use of motion-sensor camera traps for wildlife research and conservation, coupled with the inefficiency of manual image processing, means successful automation of some or all of the image analysis process is likely to save researchers time and money, as well as catalyze new uses of remote camera photos.
People love camera traps. Placed in the middle of a forest or savanna, their motion sensors trigger a photo when an animal or person passes by. They allow us to verify the presence of cool, cryptic animals at a given place and time, and grids of camera traps help us better understand site-level distributions and potential interactions among species.
As image datasets grow to include millions of photos, project teams spend increasingly greater amounts of time manually extracting the desired information — such as the presence and number of poachers or of rare and nocturnal wildlife — from the images.
In a study published last week in the Proceedings of the National Academy of Sciences (PNAS), a multinational team of scientists assessed the capacity of an advanced type of machine learning, called deep neural networks, to automatically recognize the number, species, and behavior of animals in the savanna ecosystem of Serengeti National Park in Tanzania.

From image collection to analysis
Analysis, rather than collection, of camera trap data has become a bottleneck to obtaining the desired wildlife information. Manually obtaining information from hundreds of thousands of camera trap photos has become an expensive, time-consuming process.
Moving vegetation can trigger a motion-sensor camera to take a photo, resulting in many camera trap images with no animals. When animals that are moving or relatively far from the camera trigger the photo, the image may contain only part of the animal’s body, which complicates identification and slows the analysis process.
Numerous research projects involve volunteer citizen scientists to review and analyze large numbers of images taken either by people, such as those in iSpot or iNaturalist, or camera traps, such as those in the wpsWatch or Snapshot Serengeti projects.
Scientific teams are also beginning to analyze images using automated methods. Machine learning enables computers to progressively improve performance on a specific task, such as categorizing images by species, using the raw data rather than being explicitly programmed to complete it.
For example, iNaturalist uses computer vision to help their app users (beginning naturalists) identify local species by offering them several suggestions based on what is in the photo. Wildbook uses computer vision to determine, based on an animal’s unique markings, if it is a new individual or an animal already in its database.
The authors of the current study applied a type of machine learning called deep neural networks (DNNs) to the task of automating animal identification in photos from Snapshot Serengeti (SS), which manages the largest labeled dataset of wild animal images currently available.
Neural networks are sets of algorithms, modeled loosely after the human brain, that are designed to recognize numerical patterns. They classify data when they have a labeled dataset to train on, such as the SS dataset, and they help group unlabeled data according to similarities among the example inputs.
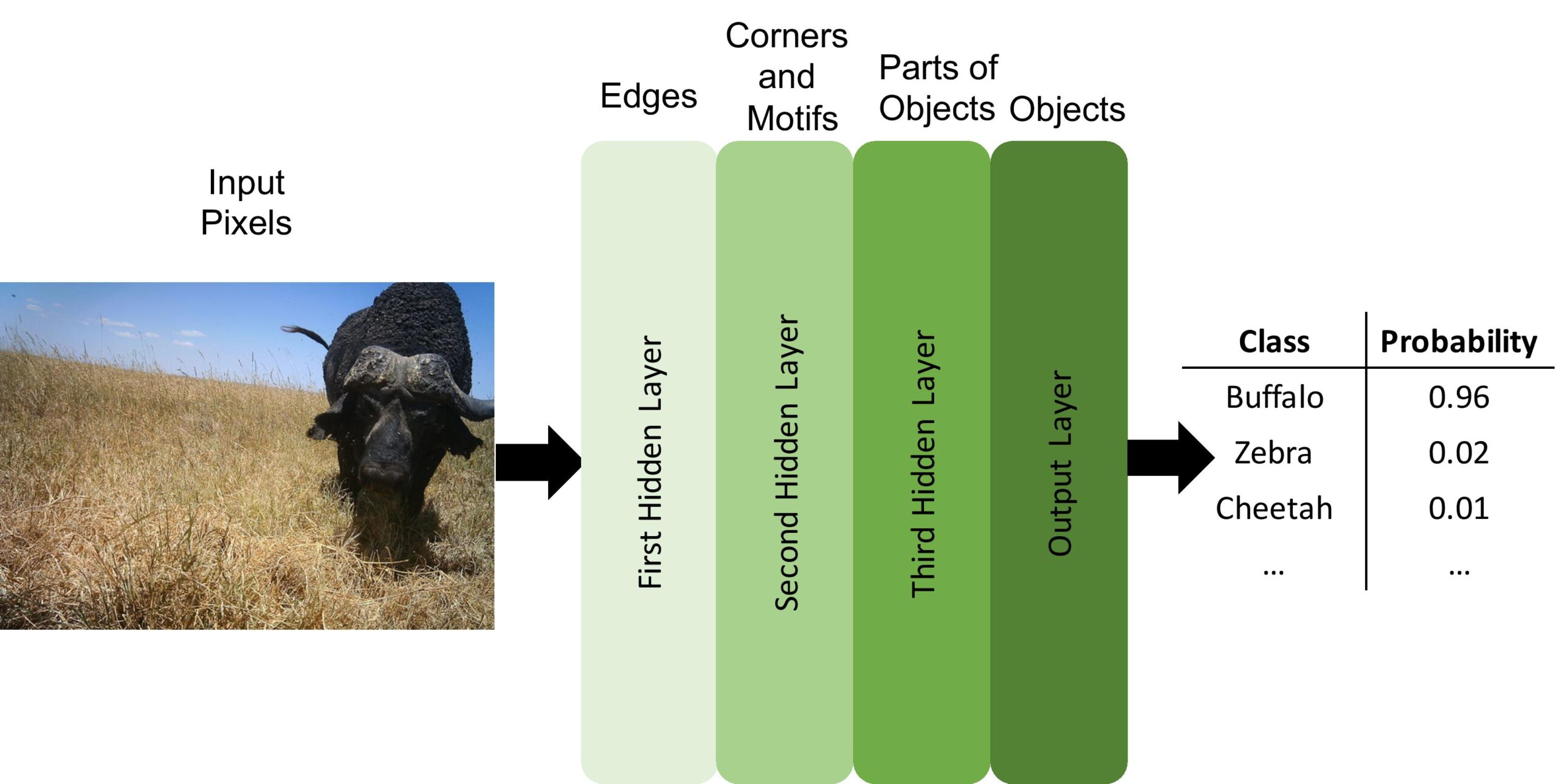
Many volunteers versus one software system
The Snapshot Serengeti project monitors and analyzes images taken by 225 camera traps installed across Serengeti National Park since 2011. It aims to understand the distribution of the park’s large mammal community and how, for example, carnivores and herbivores coexist, by analyzing images of the various species that can reveal when and where they overlap.
More than 50,000 SS volunteer citizen scientists review the images and record the number, species, and behavior of the animals in them. In their paper, the authors estimate that the volunteers’ identification of the numbers and species of animals is 97 percent and 90 percent accurate, respectively, compared to expert analysis.
In this study, the scientists trained the DNNs to identify, count, and describe the behaviors of 48 species in the SS dataset, consisting of 3.2 million images reflecting 1.2 million “capture events” (cameras take up to three images per detected motion). The massive dataset includes photos taken at various angles and lighting conditions, including shadows and darkness, and of animals that are both far away and partially off-camera.

The DNNs gradually convert raw data into concepts or object categories through several layers, or filters, of pattern recognition. For the image data in this study, the DNN identified object edges in each image, then corners and textures, then parts of objects, such as a limb or head, then the full object, such as a buffalo or cheetah.
The authors explain in their paper that the outputs of a DNN classification “are often interpreted as the DNN’s estimated probability of the image belonging in a certain class, and higher probabilities are often interpreted as the DNN being more confident that the image is of that class.”
The army of volunteers had previously recorded that just 25 percent of the SS images contained animals, so the scientists first trained and tested nine neural network models to distinguish images with animals in them from those without. For this, they used 1.4 million images, half labeled by volunteers as containing animals and half empty, as a dataset to train the models. They then used 105,000 images to test them. When compared with the human-assigned labels, all nine models correctly identified images with animals 95 to 97 percent of the time.
Automating even just this step could greatly reduce the number of images that need to be analyzed in greater detail by citizen scientists.
Next, the scientists had the models generate probabilities that the individuals in each of the 757,000 images containing animals were one of a possible 48 different species. Again, they set aside the bulk of the images to train the models, dividing the remainder into two groups to test the models.

Finding Nemo (or African plains animals…)
The scientists found that their nine algorithms could automatically identify animals by species on nearly the entire dataset and that the top-performing model identified animals with nearly 94 percent accuracy. For images that the models were confident about, the accuracy rose to 96 percent, the same achieved by human volunteers. But the system worked far less well with species that occurred only rarely in the dataset.
“What’s novel is that this is the first time it’s been shown that it’s possible to do this as accurately as humans,” co-author Margaret Kosmala, a research associate at Harvard University, told Digital Trends. “Artificial intelligence has been getting good at recognizing things in the human domain — human faces, interior spaces, specific objects if well-positioned, streets, and so forth. But nature is messy and in this set of photos, the animals are often only partially in the photo or very close or far away or overlapping. As an ecologist, I find this very exciting because it gives us a new way to use technology to study wildlife over broad areas and long time spans.”
The team also reported whether the correct species name was in the top five guesses by the network, which it was nearly 99 percent of the time. This option could help volunteers more swiftly process those images in which animals are partially obscured, far from the camera, or otherwise difficult for either the models (or people) to identify.
To determine the number of animals in an image, they assigned the image to one of 12 categories, with each representing 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11–50, or 51+ individuals, respectively. Their best model did less well (63 percent accuracy) at this task. At predicting behavior, a more complex calculation, it produced results with 76 percent accuracy.

Speeding up the process
As digital cameras become better, smaller, and cheaper, more projects will install camera traps and further build up datasets, driving the need for faster ways to analyze them.
Key to this study was the finding that DNNs can review and categorize image data far faster than humans can, and nearly as accurately. Using DNNs to process a large dataset like that of Snapshot Serengeti would, according to the scientists’ calculations, save more than 17,000 hours, or nearly 8.5 years of human labeling effort.
Automating part of the analysis process — such as eliminating images with no animals, or identifying species and behavior only for images for which the algorithm has a certain level of confidence — could on its own reduce substantial human time and cost and could facilitate analysis for smaller projects that lack volunteer support to label their image datasets.
Machine learning offers what the authors call “a far less expensive way to provide the data from large-scale camera-trap projects,” which could facilitate future research on animal behavior, effectiveness of specific conservation actions, and changes in vertebrate communities over time. They add that general algorithms that learn features from raw data (the images) save time and money, can be transferred to other places with smaller datasets, and can improve performance on different types of data.

The challenges of using computer vision
As with all methods, using computer vision techniques such as DNNs presents challenges.
To be effective, the authors state in their paper, DNNs require “lots of labeled data, significant computational resources, and modern neural network architectures.”
Co-author Jeff Clune, associate professor of computer science at the University of Wyoming, recommends that groups take advantage of both volunteers and AI in an active learning cycle.
“We could not have achieved the high performance that we did without all of the amazing work by the fantastic Snapshot Serengeti citizen-scientist volunteers,” Clune told Mongabay-Wildtech. “That said, another thing we demonstrate in this paper is that camera trap projects do not necessarily need their own labels. They could train on large, publicly available datasets (like the Snapshot Serengeti dataset we used in our project), and then transfer the knowledge learned to perform well on a new project that only has a few labeled images.”
Also, DNNs become biased toward classes (species) with more examples and may not invest in learning the features of species or behaviors that rarely appear in the photos, which could make the technology less useful in forest systems. Nevertheless, Clune said, “The system performs surprisingly well even when only parts of the animal are visible, but of course it will not work if the animal is entirely occluded.”

Reference
Norouzzadeh, M. S., Nguyen, A., Kosmala, M., Swanson, A., Palmer, M. S., Packer, C., & Clune, J. (2018). Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proceedings of the National Academy of Sciences, 201719367.
The scientists have made their models and their open-source code freely available on GitHub.
FEEDBACK: Use this form to send a message to the editor of this post. If you want to post a public comment, you can do that at the bottom of the page.











