- A global comparison of ten satellite-based forest datasets found striking disagreement about where forests are located, with only about a quarter of mapped forest area recognized by all sources. Differences in definitions, resolution, and methodology mean that estimates of forest extent vary widely depending on the map used.
- The inconsistencies are greatest in dry forests and fragmented landscapes, where sparse tree cover makes classification difficult. Even small technical choices—such as canopy thresholds or sensor type—can determine whether an area counts as forest at all.
- These discrepancies translate into large differences in real-world indicators. Estimates of forest carbon in Kenya, forest-proximate poverty in India, and habitat loss in Brazil varied dramatically across datasets, with potential implications for funding, policy, and conservation priorities.
- Because forest maps underpin climate targets, biodiversity planning, and development decisions, the authors urge treating estimates as ranges rather than precise figures and testing results across multiple datasets. Greater standardization and transparency, they argue, will be essential for credible monitoring of global environmental goals.

A deceptively simple question underlies many global environmental policies: where, exactly, are the world’s forests? A new study suggests the answer depends heavily on which map one consults—and that the differences are large enough to reshape climate targets, conservation priorities, and development spending.
Researchers Sarah Castle, Peter Newton, Johan Oldekop, Kathy Baylis, and Daniel Miller compared ten widely used global forest datasets derived from satellite imagery. These products underpin everything from carbon accounting to biodiversity assessments. Yet they rarely agree. Across the area identified as forest by at least one dataset, only about 26% was classified as forest by all of them. Even after adjusting maps to a common spatial scale, agreement improved only modestly.
This divergence stems partly from differing definitions. Some datasets count areas with sparse tree cover as forest; others require dense canopy. A threshold of 10% canopy cover, for example, will include savannas and woodland mosaics, while a 70% threshold captures only closed forests. Resolution also matters. High-resolution imagery can detect narrow forest strips or small patches that coarser data miss. Methodological choices—such as sensor type, machine-learning algorithm, and training data—introduce further variation.

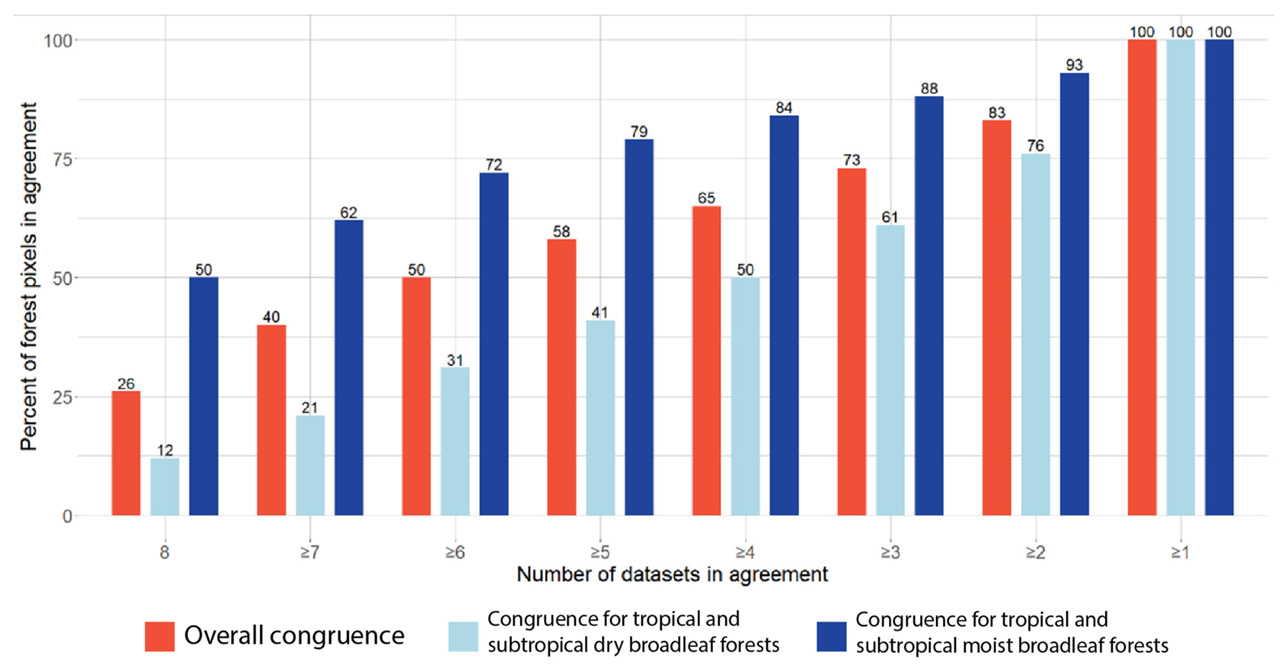
Disagreement is not uniform. Moist tropical forests, where tree cover is continuous, show relatively high consistency across datasets. By contrast, dry forests and fragmented landscapes exhibit far less agreement, with some biomes showing full consensus on as little as 12% of forested area. These are often precisely the regions where conservation decisions are most contested.
The authors test how these discrepancies translate into real-world indicators. In Kenya, estimates of how much carbon is stored in forests varied dramatically depending on the dataset used—from roughly 2% to 37% of the country’s total biomass carbon. Maps that produced similar national totals did not necessarily agree on where the carbon was located, complicating efforts to target mitigation projects.
A second case study examined India, where millions rely on forests for livelihoods. Using identical population and poverty data but different forest maps, estimates of the number of forest-proximate people living in poverty ranged from about 23 million to more than 250 million. Such disparities could influence how development funds are allocated or how the social impacts of conservation policies are assessed.
In Brazil, the researchers considered habitat for the endangered white-cheeked spider monkey. Even datasets designed specifically to track forest loss agreed only partially on where deforestation had occurred, with less than half of mapped loss overlapping between two prominent products over several years.

These differences matter because satellite-derived forest maps increasingly serve as the empirical backbone of global environmental governance. Governments use them to report progress toward climate commitments. NGOs rely on them to prioritize interventions. Investors employ them to evaluate nature-related risks. If the underlying maps diverge widely, policy conclusions may hinge on technical choices made far from the field.
The study does not argue that any single dataset is “correct.” Each is designed for particular purposes and trade-offs. Instead, the authors recommend treating forest estimates as ranges rather than precise figures. They suggest that results be tested against alternative datasets, a practice common in other scientific fields but less routine in large-scale land-cover analysis.
Longer term, they call for greater standardization. Shared definitions, clearer reporting of uncertainty, and harmonized protocols could reduce confusion and improve comparability. Without such efforts, the authors warn, a “fundamental technical choice” may continue to influence how resources are distributed and how progress toward global goals is judged.
Forests remain central to climate mitigation, biodiversity protection, and rural livelihoods. Yet this research suggests that before debating how to manage them, policymakers may need to confront a more basic problem: agreeing on where they are in the first place.
Citation:
- Sarah E. Castle, Peter Newton, Johan A. Oldekop, Kathy Baylis, and Daniel C. Miller (2026). Global forest dataset incongruence creates high uncertainties for conservation, climate, and development policy. One Earth (9) 101558. https://doi.org/10.1016/j.oneear.2025.101558