- Sara Beery is a computer vision expert with an unlikely path to science: having started out as a ballerina, her goal now is to help solve problems in conservation technology.
- She takes two approaches to conservation tech — a top-down one for solutions that can be applied to a wide range of problems, and a bottom-up one tailored for specific challenges — and works in the field to make sure they actually work.
- Beery helped create Microsoft’s AI for Earth MegaDetector, a model that helps detect animals in camera trap data, and collaborates with the ElephantBook project in Kenya to automate the identification of elephants.
- In an interview with Mongabay, Sara Beery talks about her path to conservation tech, how she combines the best of both human and artificial intelligence to solve problems, and why fieldwork is key to ensuring that tech solutions are usable and accessible.
Some people know that they want to be scientists from an early age. Not so with Sara Beery. The computer vision expert got started on her path to science in an unlikely way: as a ballerina. While working for the Atlanta Ballet, Beery saw ads for seminars at Georgia Tech. And although it was the free food that got her in the door, the topics piqued her interest over time.
“It was the first time in my life I ever realized that engineering and computer science and technology could be tools for social good,” says Beery, now a Ph.D. candidate at the California Institute of Technology.
Today, the former ballerina now looks at how artificial intelligence can be implemented in conservation to streamline data analysis, help scientists be more efficient, and create technology that is actually useable and accessible.

“I feel like ballet taught me how to have a very good attitude about failure. And take all those failures as lessons for making improvements down the road,” she says.
And she’s done just that: Beery sees problems in conservation tech and fixes them. One issue she’s trying to solve is the problem of too much data, especially when using camera traps. She sees a universal need in the scientific community to filter out empty images and accurately detect animals in the remaining images.
“Camera traps collect a ton of data,” she says. “It is incredibly time-consuming for a human to go through all of that data … and get out the information that’s hidden in all those pixels.”
So Beery helped develop Microsoft’s AI for Earth MegaDetector, a model that detects animals in camera trap photos.
Working in the field is also an important part of Beery’s research. Oftentimes with machine learning, solutions and changes don’t always translate to the field. So she collaborates with ElephantBook in the Masai Mara in Kenya, keeping tabs on elephants using a hybrid human-AI approach that she thinks is an important next phase in conservation technology.
That approached is premised on the fact that humans are better learners than machines and can better identify the changes in individual elephants and the population. For instance, particular elephants may get new tears in their ears, or some may come and go within the population. These are challenges that machine learning is not great at, she says. One added benefit is that community members become elephant experts in the process.
“Part of what I want from my career is to make sure that the tools that I’m building are solving the problem that I’m purporting to solve and are usable by the community,” she says.
Mongabay’s Caitlin Looby talked recently with Sara Beery about her path from ballet to computer vision, how her works helps streamline analysis of camera trap data, and how she travels to the field to make sure technology is useable, scalable and accessible. The interview was lightly edited for clarity and length.
Mongabay: I’d like to hear about your background. How did you get started in conservation technology? Have you always been interested in AI?
Sara Beery: It was a bit of a weird journey. I have always been really passionate about the environment and conservation. And that’s just probably in part due to how my parents raised me. They’re like happy Pacific Northwest hippies, who care very deeply about the world. But my first passion was ballet. I started doing ballet at 4; I started training rigorously at around 11 or 12. And I got my first job at 16 and moved across the country and was a professional ballerina for six years. A bit of a different path.
My first job was with the Atlanta Ballet. And young ballerinas don’t get paid much. I was really broke and hungry all the time. And I lived in a cheap area of Atlanta, which also happened to have a lot of college students who went to Georgia Tech, called Home Park.
And so there used to be ads people put up on the telephone poles that would be like “come to the seminar, free food.” And I started going to seminars at Georgia Tech, and pretending I was a student for free food, but then you have to stick around for the talk.
It was the first time in my life I ever realized that engineering and computer science and technology could be tools for social good. I really had not been introduced to that as a concept before. I thought that computer science was for people who liked video games. And so that sort of opened my eyes to the possibility. Then when I did resign, I decided to retire at the ripe old age of 22 from my ballet career.
I went back to school to study electrical engineering, because I wanted to work on the shift to green energy. And then just sort of by one of those lucky things, the chair of my department was working on a research project with Panthera doing individual snow leopard recognition with computer vision. And I’d never heard of computer vision.
I wanted to figure out what research is and got put on this project and completely fell in love both with the concept of using computer vision and AI to work on these wildlife conservation problems. With the concept of research in general, I loved how creative it was. It felt like going back to my artistic roots. I worked on that project throughout undergrad and then decided to get a Ph.D. and keep pursuing this sort of AI for conservation perspective.

Mongabay: Is there anything you take from your dance background that you use in your science today?
Sara Beery: I think that dance really helped me with a couple things. With ballet, you face failure all the time. And I think in research, we deal with failure. A lot of stuff goes wrong, stuff breaks, and I feel like ballet taught me how to have a very good attitude about failure. And take all those failures as lessons for making improvements down the road.
And then I think the other major skill that working as an artist taught me was just how to communicate well with a bunch of different types of people. I think that we should be teaching scientists to communicate more than we do, because I really have seen how much those communication skills have helped me in my career.
Mongabay: Tell me about the Microsoft AI for Earth MegaDetector project. What are some of the goals and how has it been successful so far?
Sara Beery: That project started as my sort of initial research project [on snow leopards] when I was just starting my Ph.D. at Caltech. One of the things that I noticed in that project was that there was a big need to be able to identify if this is a snow leopard at all. But then much more broadly than that, just anyone who’s working with camera trap data wants to know what animals I saw in my camera.
It started as a project where I was partnering with local Southern California researchers at the United States Geological Survey and the National Park Service, and I was trying to build camera trap species classification models for them. And our initial results looked good, we were getting nearly perfect accuracy. Machine learning can just do this. Sort of around the same time, there started to be some papers that were coming out saying that machine learning has solved camera trap species ID. We don’t need to worry about this anymore.
But in discussions with my collaborators, I realized that they want this to be able to work on any new camera they put out. We know machine learning is very good at memorizing correlations in the data that are not actually good at what we want it to learn. It might just be learning, for example, that in this specific camera trap if you see this background then you’re more likely to be seeing a bobcat, potentially learning something that you don’t want it to.
I took the data that we’ve collected, and I was like, let’s try our models in this scenario. We’ll train on these ones and test on these. And what we saw was there is a major drop-off in performance with these new camera traps — we’re talking about 95% accuracy to 60%.
Then, I went to work with Microsoft as an intern, and Dan Morris and I kind of took this and built MegaDetector … And let’s see if we can build an animal detection model for camera trap data that will work anywhere in the world for any species.
And so, the “mega” in there is sort of like a tongue in cheek reference to this effort to work with a bunch of different partners from tons of organizations, collect their data, parse it into a single sort of standard format … the “mega” is trying to get everyone to work together. To build something that works better for everyone. Since that internship, the project has really taken off.
Mongabay: What was the main problem you were trying to solve with this project?
Sara Beery: When it comes down to it, the big problem that people face when they’re trying to use camera traps to do conservation, research or to manage a protected area is that camera traps collect a ton of data. For example, I put out a network of camera traps in Kenya, 100 camera traps, and we’ve collected 18 million images in the last two years.
As you can imagine, it is incredibly time-consuming for a human to go through all of that data and process it to be able to then use it and get out the information that’s hidden in all those pixels and be able to actually use it for their downstream research.
And our goal is how do we make that scalable? How do you make humans more efficient so that they can get through the data in a timely manner? Before we started working with Idaho Department of Fish and Game, they were five years behind on their processing and they were collecting data every year so you just can never catch up. And then if you’re getting the results of your monitoring five years late, and you’ve already made policy changes, you don’t find out whether those policy changes were good or not in a timely manner, which I think is really important.

Mongabay: It’s my understanding that you do some fieldwork as well. Can you tell me a little bit more about that? Why is it important for you to get out in the field?
Sara Beery: I started building more of a community around AI for conservation, and I started a Slack channel to try to find out who else was working on these problems. And now it’s like 600 people and so there’s a lot of interest in the research community. But what I was seeing consistently is people would publish a paper on some cool project that was really promising in a lot of cases. But then those projects weren’t getting used. Some of the technology was being developed, but then it wasn’t being used by the conservationists that it might benefit.
And I first started going out into the field because I really felt like part of what I want from my career is to make sure that the tools that I’m building are solving the problem that I’m purporting to solve and are usable by the community and are providing value in some way. I wanted to really understand firsthand what those bottlenecks were like: Why are these why are these systems not being used? What are the reasons that they’re not accessible? Every time I go to the field, I learn a lot more from the people who are there on the ground, what is needed and what the bottlenecks are.
Something like the MegaDetector, for example, is in the cloud. And I have lots of different models that work in different parts of the world that are very useful, but they’re in the cloud.
I secured funding and got these camera traps and went to Kenya and put them out so that we could do this comparative study of doing individual zebra identification from camera trap data versus from data taken by humans. The plan was to work with this local company that has the best bandwidth in Kenya. We knew that there was no way we were going to be able to get the data from the research camp from Mpala Research Center to the cloud because they just they don’t have the bandwidth there. But we were going to drive the hard drives into town and then this local company would have the speed to be able to do the upload. And we tried it the first time and they started doing speed tests. And they realized that getting a single hard drive into the cloud was going to take six months and be incredibly expensive for them. This is not feasible.
Now, our workaround, which gives me pain, is we put the hard drives in a box and we ship them across the world to Caltech and I upload them at Caltech where it’s much faster. It just really shows this is a big problem. Trying to address that that challenge of getting these large volumes of data from the field to the machine learning model is complex.
And then there’s additional challenges. You want to bring the machine learning model to the field because you need super-fast computers or access to resources that some of these local centers don’t have. Understanding why the things aren’t being used and then trying to come up with good ways to fix those problems, I think is why it’s important for conservation technologists to go to the field even if most of their work is typing on a computer.
Mongabay: Tell me a little bit more about the work that you do with ElephantBook.
Sara Beery: When I was out in Kenya placing these camera traps, I also I wanted to talk to more than one set of conservationists. There’s tons of amazing work across Kenya going on in conservation. I spoke to WWF and the World Agroforestry Centre and then I went down to the Mara to visit with the Mara Elephant Project and their director of research and conservation [Jake Wall], who’s an amazing conservation technologist. He developed most of the sort of programming behind Earth Ranger, which is a commonly used platform for managing data for protected areas. We were talking about what some of their challenges are in doing elephant monitoring.
Traditionally, one of the ways that we do try to monitor these elephant populations is to collar specific key elephants in the population, which costs $15,000 to $20,000 per elephant and requires a bunch of expertise and upkeep. Another approach has been doing long-term monitoring of populations with visual re-identification: you see an elephant and you’re able to visually re-identify which elephant it is, and then you can use that information to track its behavior and movement patterns in the social networks.
But that’s traditionally relied heavily on both the populations being small enough and enclosed enough that a person can learn all the elephants. It’s relied heavily on this sort of small set of experts who are able to look at an elephant and tell you who it is. And it’s incredibly difficult to have a sense of reproducibility in that scenario because you don’t really have any data you’re collecting and there’s no way to go back to it.
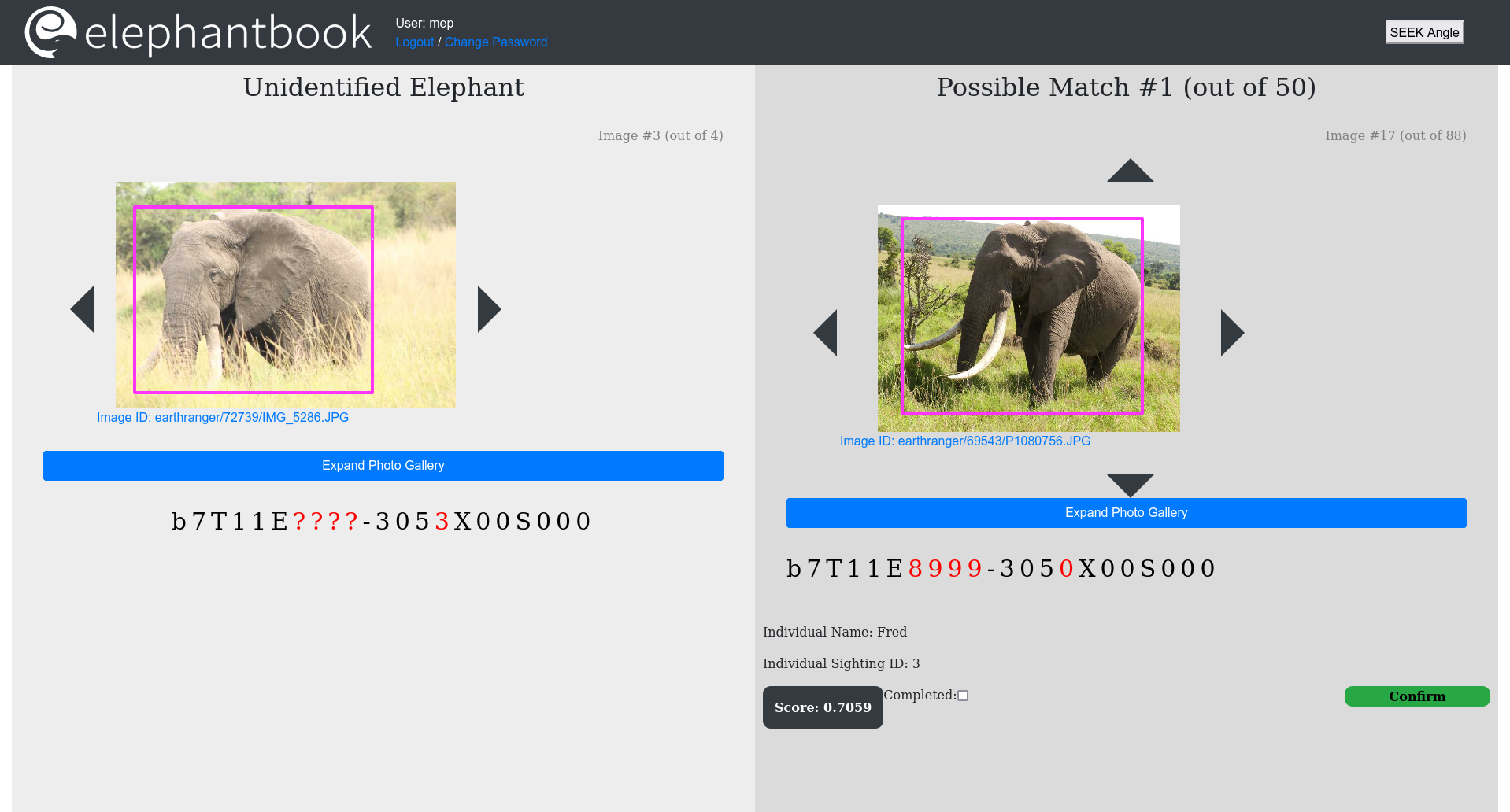
ElephantBook is a system that tries to use automated methods to make that re-identification of elephants faster and more accessible for non-experts. And that allows it to be done quickly and well.
There have been some traditional ways that people have tried to make this more accessible to non-experts try to help direct human attention to the parts of the elephant that make it identifiable. And these include drawings of the edges of the elephant ears. Recently, a group of researchers led by Michelle Henley down in South Africa at Elephants Alive made a simplified version of what they call System for Elephant Ear Pattern Knowledge (SEEK). Our contribution is systematizing the SEEK labeling, so a human labels the code for a given elephant. And then we run computer vision algorithms that extract the contour of the ear and do contour-based matching.
This combination of the human-attributed labels in the coding of the elephants, plus the computer vision systematically gives us better results. And we have sort of creative ways that we’re combining that information and then we rely on humans doing verification for every individual.

Mongabay: You use a human-AI hybrid approach with ElephantBook. How does this work?
Sara Beery: I think the reason that it works better than either one of those is you’re combining the best of both worlds. AI is really fast, but it is prone to mistakes. And it’s prone to mistakes specifically in scenarios where there’s either little available training data for a given object of interest, or where it might be asked to do something outside of the scope of what it’s been trained to do. If the objects are going to change over time, that’s also something that it’s hard for the model to handle. If it’s been trained to recognize an elephant with a given contour, and then that elephant gets a huge tear in its ear, all of a sudden that contour is significantly different. That can be difficult for machine learning model to handle.
Individual identification really encompasses those challenges. In the Mara, there are estimated to be around 8,000 elephants, which are changing over time, and the population is changing. There’s deaths and births and transient elephants that come through. You have to be able to handle all of these challenges that machine learning is traditionally just not super great at. There’s been a lot of interesting advancements recently and machine learning is getting better at these things, but it’s still not good enough to be trusted to do them well.
And that’s where humans come in. Humans are remarkably good at learning stuff from a few examples. They can robustly handle new concepts. And that robustness of being able to sort of really trust the database that we’re creating, by relying on both, is important.
We’re working with the long-term monitoring team that that we hired at the Mara Elephant Project. It’s a team of rangers who are on the ground and they go out and taking elephant sightings every day. And one of the really cool things is, none of them were elephant experts to start with. But they’re providing additional training data all the time that’s improving our machine learning model, and then also the system is helping direct their attention and teaching them what these identifiable characteristics are, which is teaching them to be better experts. The human expertise is getting better, and the machine learning expertise is getting better simultaneously.
Mongabay: It seems like your work is done at two different scales. MegaDetector is very general and broad, while ElephantBook is specific and tailored. Can you tell me more about that?
Sara Beery: This was a conscious choice as part of my Ph.D. They represent really two ends of the spectrum of how you can have conservation impact with technology. And I really wanted to explore that spectrum and understand where those tradeoffs are. Essentially, it’s the difference between a top-down approach and a bottom-up approach. With ElephantBook, we really designed a system that solved a problem end-to-end for a given user. We started from nothing and now we have a system that’s deployed, and we’re building up a very robust database of the elephant population.
Whereas with the MegaDetector, it was more about understanding that there was a universal need for filtering on empty images, for example, and camera trap data. And even though the original goal of the project was species ID, it was also recognizing that there was this opportunity to provide a tool that might not do species ID for everyone in the world. But it is already useful for basically everyone in the world who uses camera trap data. And making that tool accessible, understanding what the needs of the community are, and then providing tools that fix them.
And so I think if you’re a computer vision researcher, understanding the specificity of the problem and how well it might generalize will have impact with your solutions.
Mongabay: What are some of the limitations in using technology, and specifically with AI?
Sara Beery: How it translates to solutions. I think it just enables conservation groups to take the resources they were spending on data processing, and migrate those resources to analysis and problem-solving, which is really where I think their resources should be going. Partners will report anywhere from like 50-80% reduction in time spent labeling camera trap data and financial costs to pay people to look at all of the images. It’s a lot of resources that are freed up for other things. Especially when you consider how many different projects are using the model.
AI makes things possible that just weren’t possible before. It wasn’t feasible for the Mara Elephant Project to do long-term population modeling and monitoring because they didn’t have a local expert who already knew all the elephants. It wasn’t clear how to train someone to do that. And they definitely can’t collar every elephant in the 8,000-elephant population. There was not a way for them to do what they’ve been able to do because we’ve incorporated this systematic approach.
Mongabay: How does your work translate to solutions and policy changes?
Sara Beery: The process of understanding how AI is going to play a part in policymaking is still very much underway. Governments are still in the process of figuring out when AI should or should not be used or if it should be trusted when making policy decisions and how AI should be regulated. I think in the context of conservation, this is requiring rigorous standards for continual AI verification and validation for any model that’s going to be used as a policy. But we’re still in that process. As far as how it’s contributed to policy changes, I think we’ll see.
Mongabay: What are some of the next steps that you want to tackle with your work?
Sara Beery: I think from the research side stuff that I’m really interested in, how do we incorporate more of the vast and very well-studied scientific knowledge into these machine learning models? One example of that is with the elephant identification. Most re-identification systems and computer vision currently operate as a one-to-one: Here’s an image of an elephant, tell us which elephant.
There’s a lot of social structure and an elephant population. You don’t see an elephant alone. Usually you’ll see elephants in social groups. And when a human is doing this type of identification, they’ll look at the entire group of elephants. They’ll maybe identify key individuals that are super recognizable, and maybe one of them is missing a tusk. And then they use their prior knowledge about the social network, who those elephants are likely to be hanging out with, to make identifying the other ones in the group easier. This is just one example of a way to incorporate that into your system, but we’re currently working with researchers at the University of California, Los Angeles, and Rensselaer Polytechnic Institute to try to come up with a systematic model for incorporating social information into re-identification of animals.
A past example of a really successful approach in that frame [incorporating what humans can do into machine learning] is with camera trap data. Human experts use temporal information a lot: Let’s look at the ones before and after it. Last week, we saw an animal that looked a lot like one that was the same size, same shape, but this picture was blurry…
By giving a machine learning model access to long-term temporal information, you can access this bank of memories, and it gets to use a flexible approach. We saw remarkable improvements on species identification. It’s just heavily informed by the way that human experts are doing things and so the more that we can design systems that are that are not just like operating in a vacuum, and solving problems in a way that doesn’t fit the problem at hand … the more that we can really incorporate intuition from the human experts into the frameworks we are developing, I think, the better.
Mongabay: How do you define success when it comes to conservation technology?
Sara Beery: Is it providing value? And is that value enabling something that wasn’t possible before? I think it’s not a success if it takes more effort and more money and then doesn’t work and you end up doing it the old way anyway.
Any new technological development, any research question is something that is fundamentally prone to failure. There will be mistakes and I think that this is where the scientific research community comes in. Because research is the space where you are expected to be prototyping and testing out these new approaches. If we do that very rigorously, and then we partner with local organizations and we do sort of these first prototyping passes, and really make sure that the system’s working as expected…
And I think one thing that I have seen that’s been really frustrating is people not taking the time to rigorously test their assumptions, and publishing papers and blog posts saying machine learning is great. It’s going to work for you, everyone should buy 20 drones because drones are going to be the new thing that allows you to monitor your populations.
And I think what ends up happening when people make these claims that aren’t well vetted in very public ways is that we start to see distrust in technology building up from the conservation organizations because they put in a lot of effort. They put in a lot of money that they don’t necessarily have and then they don’t get something that works. And when that happens, they’re not going to take that risk again. And I think it’s on us as conservation technologists to be very careful about the claims that we’re making.

Caitlin Looby is the 2021 Sue Palminteri WildTech Reporting Fellow, which honors the memory of Mongabay Wildtech editor Sue Palminteri by providing opportunities for students to gain experience in conservation technology and writing. You can support this program here.
Editor’s note: This story was supported by XPRIZE Rainforest as part of their five-year competition to enhance understanding of the rainforest ecosystem. In respect to Mongabay’s policy on editorial independence, XPRIZE Rainforest does not have any right to assign, review, or edit any content published with their support.